怎么设计一个短链系统?
短链系统
短链服务的鼻祖是TinyURL,是最早提供短链服务的网站,目前国内也有很多短链服务:新浪(t.cn)、百度(dwz.cn)、腾讯(url.cn)等等。
短链的好处
- 太长的链接容易被限制长度
- 短链接看着简洁,长链接看着容易懵
- 安全,不想暴露参数
- 可以统一链接转换,当然也可以实现统计点击次数等操作
短链的原理
短链是通过服务器重定向到原始链接实现的。
控制台执行命令curl -i http://t.cn/A6ULvJho,结果如下:
HTTP/1.1 302 Found
Date: Thu, 30 Jul 2020 13:59:13 GMT
Content-Type: text/html;charset=UTF-8
Content-Length: 328
Connection: keep-alive
Set-Cookie: aliyungf_tc=AQAAAJuaDFpOdQYARlNadFi502DO2kaj; Path=/; HttpOnly
Server: nginx
Location: https://www.howardliu.cn/how-to-use-branch-efficiently-in-git/index.html??spm=5176.12825654.gzwmvexct.d118.e9392c4aP1UUdv&scm=20140722.2007.2.1989
<HTML>
<HEAD>
<TITLE>Moved Temporarily</TITLE>
</HEAD>
<BODY BGCOLOR="#FFFFFF" TEXT="#000000">
<H1>Moved Temporarily</H1>
The document has moved <A HREF="https://www.howardliu.cn/how-to-use-branch-efficiently-in-git/index.html??spm=5176.12825654.gzwmvexct.d118.e9392c4aP1UUdv&scm=20140722.2007.2.1989">here</A>.
</BODY>
</HTML>
从上面的信息可以看出来,新浪做了 302 跳转,同时为了兼容性,还返回用于手动调整的 HTML 内容。整个交互流程如下:

短链生成方式
据统计,目前全球有 58 亿的网页,Java 中 int 取值最多是 2^32 = 4294967296 < 43 亿 < 58 亿,long 取值是 2^64 > 58 亿。所以如果是用数字的话,int 勉强能够支撑(毕竟不是所有网址都会调用短链服务创建短链),使用 long 就比较保险,但会造成空间浪费。
新浪微博使用 8 位字符串表示原始链接,这种字符串可以理解为数字的 62 进制表示,62^8 = 3521614606208 > 3521 亿 > 58 亿,也就是可以解决目前全球已知的网址。62 进制就是由 10 个数字 + (a-z)26 个小写字母 + (A-Z)26 个大写字母组成的数。
哈希算法
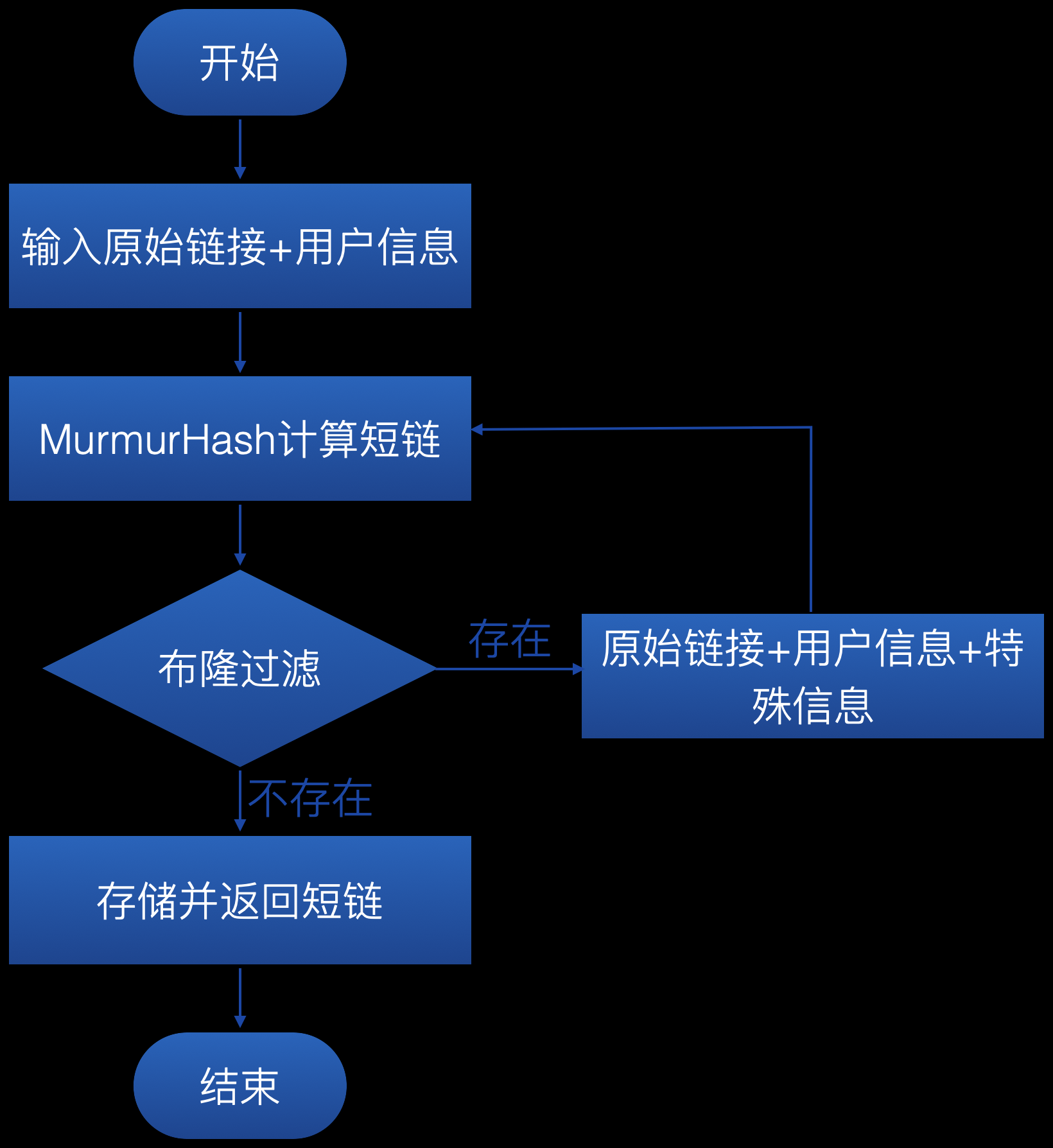
对原始链接取 Hash 值,是一种比较简单的思路。有很多现成的算法可以实现,但是有个避不开的问题就是:Hash 碰撞,所以选一个碰撞率低的算法比较重要。
推荐MurmurHash 算法,这种算法是一种非加密型哈希函数,适用于一般的哈希检索操作,目前 Redis,Memcached,Cassandra,HBase,Lucene 都在用这种算法。
对于碰撞问题,最简单的一种思路是,如果发生碰撞,就给原始 URL 附加上特殊字符串,直到躲开碰撞为止。具体操作如下图:
发号器
这个就是不管来的是什么,通过集中的统一发号器,分配一个 ID,这个 ID 就是短链的内容,比如第一个来的就是https://tinyurl.com/1,第二个就是https://tinyurl.com/2,以此类推。当然可能一些分布式 ID 算法上来就是很长的一个序号了。为了获取更短路,还可以将其转为 62 进制字符串。
- Redis 自增:Redis 性能好,单机就能支撑 10W+请求,如果作为发号器,需要考虑 Redis 持久化和灾备。
- MySQL 自增主键:这种方案和 Redis 的方案类似,是利用数据库自增主键的提醒实现,保证 ID 不重复且连续自动创建。
- Snowflake:这是一种目前应用比较广的 ID 序列生成算法,美团的 Leaf 是对这种算法的封装升级服务。但是这个算法依赖于服务器时钟,如果有时钟回拨,可能会有 ID 冲突。(有人会较真毫秒中的序列值是这个算法的瓶颈,话说回来了,这个算法只是提供了一种思路,如果觉得序列长度不够,自己加就好,但是每秒百万级的服务真的又这么多吗?)
对于统一发号器这种方式,还需要解决的一个问题是:如果同一个原始链接,应该返回相同的短链还是不同的短链?
答案是根据用户、地点等维度,相同的原始链接,返回不同的短链。如果判断维度都相同,则返回相同短链。这样做的好处是,我们可以根据短链的点击、请求信息,做数据统计。对于短链,我们牺牲的只是一些存储和运算,但是收集的信息却是无价的。
短链存储
一般这种数据的存储无非就两种:关系型数据库或 NoSQL 数据库。有了上面的创建逻辑,存储就是水到渠成的了。下面给出 MySQL 存储的建表语句:
CREATE TABLE IF NOT EXISTS tiny_url
(
sid INT AUTO_INCREMENT PRIMARY KEY,
create_time DATETIME DEFAULT CURRENT_TIMESTAMP NULL,
update_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP NULL ON UPDATE CURRENT_TIMESTAMP,
version INT DEFAULT 0 NULL COMMENT '版本号',
tiny_url VARCHAR(10) NULL COMMENT '短链',
original_url TEXT NOT NULL COMMENT '原始链接',
# 其他附加信息
creator_ip INT DEFAULT 0 NOT NULL,
creator_user_agent TEXT NOT NULL,
# 用户其他信息,用于后续统计,对于这些数据,只要存储影响创建短链的必要字段就行,其他的都可以直接发送到数据服务中
instance_id INT DEFAULT 0 NOT NULL,
# 创建短链服务实例ID
state TINYINT DEFAULT 1 NULL COMMENT '-1无效 1有效'
);
短链请求
存储完成后,接下来就该使用了。
通常的做法是会根据请求的短链字符串,从存储中找到数据,然后返回 HTTP 重定向到原始地址。如果存储使用关系型数据库,对于短链字段一般需要创建索引,而且为了避免数据库成为瓶颈,数据库前面还会通过缓存铺路。而且为了提高缓存合理使用,一般通过 LRU 算法淘汰非热点短链数据。流程如下:
短链请求 -> 布隆过滤器 -> 缓存 -> 数据库
图中的布隆过滤器是为了防止缓存击穿,造成服务器压力过大。
这里还有一个问题:HTTP 返回重定向编码时使用 301 还是 302,为什么新浪微博会返回 302,而不是更加符合语义的 301 跳转?
来看看HTTP状态码中301和302分别是什么含义:
- 301,代表永久重定向。也就是说,浏览器第一次请求拿到重定向地址后,以后的请求,都是直接从浏览器缓存中获取重定向地址,不会再请求短链服务。这样可以有效减少服务请求数,降低服务器负载,但是因为后续浏览器不再向后端发送请求,因此获取不到真实的点击数。
- 302,代表临时重定向。也就是说,每次浏览器都会向服务器发起请求获取新的地址,虽然会给服务器增加压力,但在硬件过剩的今天,这点压力比起数据简直不值一提。所以,302 重定向才是短链服务的首选。